Tech Stack
Before / After
LLM Reads Everything
No measured tradeoffExpensive reasoning is spent equally on useful and low-value adverse-event reports.
Nobody knows what quality is lost when calls are reduced.
Models exist separately without a shared routing decision.
Cost reduction is a hope, not an evaluated result.
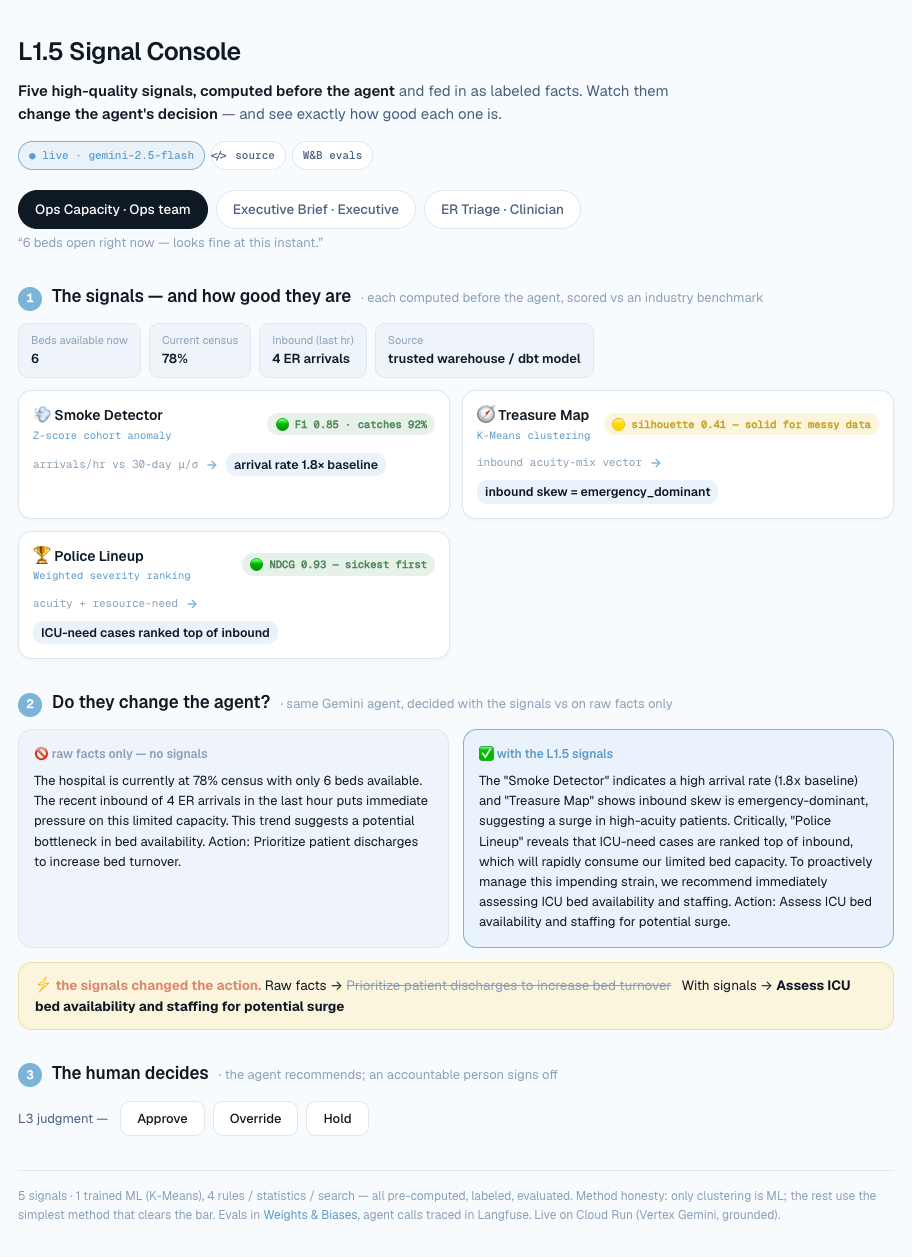
Signals Decide What Deserves Attention
Evidence before optimizationSmoke Detector / AnomalyIsolationForest flags the unusual reports first — the 30 it flags carry 4.8 reactions on average vs 2.3 for the rest, so the LLM investigates outliers instead of scanning everything.
Treasure Map / ClusteringKMeans groups reports into cohorts (silhouette 0.61 at k=4 — modest structure on n=300, reported honestly) so patterns are analyzed, not individual reports.
Traffic Light / ClassificationA classifier over TF-IDF reaction-text + numeric features predicts whether a report is serious — F1 0.877 in 5-fold CV (text features lifted it past the no-text 0.846), sorting NOW / WAIT before the LLM spends a token.
Ranking EngineReports are ranked by P(serious): precision@200 is 1.0 vs 0.55 for a random queue, so the highest-impact reports reach the LLM first.
Similar Cases / LookalikeTF-IDF over reaction text retrieves comparable reports (Recall@5 0.34 for same-drug siblings), so the LLM reasons with examples instead of from scratch.
The Router Earns Its Cut — HonestlyScaling to ~5,000 real reports and adding TF-IDF features over the reaction text turned a measured tradeoff into a real win: the router cuts 30% of LLM calls while holding serious-report recall at 0.954 (≥95%), beating the route-everything baseline. The full cost-recall curve is shown — deeper cuts trade recall, and that's stated, not hidden.