🧠 AWS
Bedrock Claude + Titan
🔍 pgvector
Postgres vector search
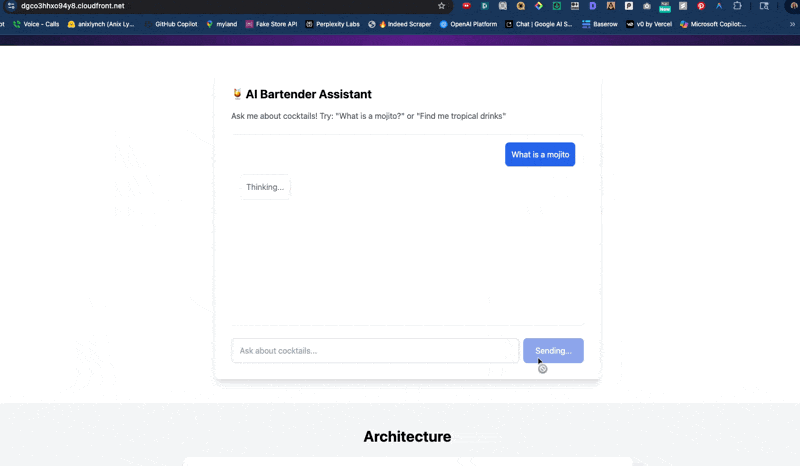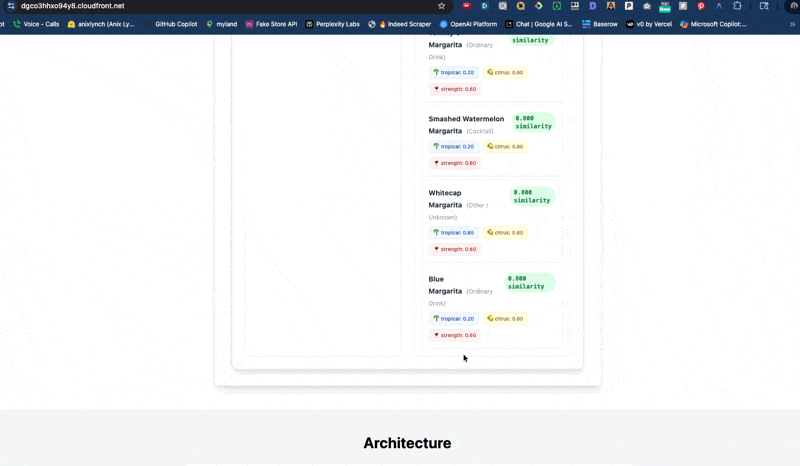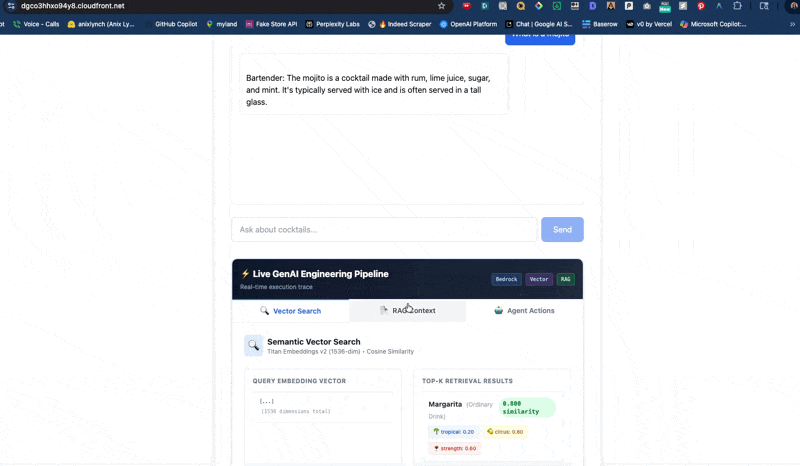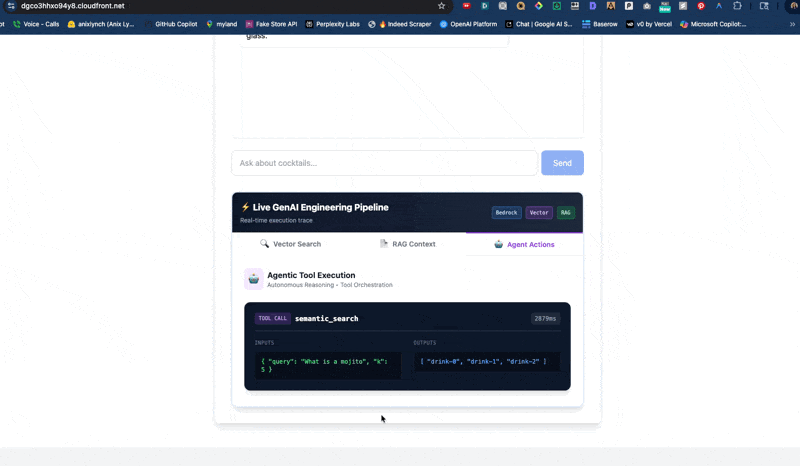
🔁 RAG
Chunk → retrieve → answer
🏭 E2E
Ingest to generation
Tech Stack
PythonAWS BedrockpgvectorRAGPostgreSQLLangChainboto3DockerFastAPI
Before / After
Before
Before
Keyword cocktail searchQuestion
↓
SQL LIKE search
↓
Exact-name match
↓
Misses the vibe
×
Ask for 'something smoky and bitter' and a keyword search shrugs.
×
Needs the exact ingredient or drink name to find anything.
×
No semantic understanding — it matches letters, not meaning.
×
Real vector search usually means a managed vector DB bill.
After
After
Bedrock RAG platformQuestion
↓
Semantic retrieve
↓
Bedrock grounds
↓
Real answer
✓
Vibe SearchAsk for 'smoky and bitter' and pgvector surfaces the mezcal negroni — even when those exact words aren't in the recipe.
✓
Model SwapClaude or Titan behind one Bedrock API. Change the brain without touching the application code.
✓
No-VendorDB VectorsProduction semantic search on plain Postgres + pgvector — no managed vector DB to pay for.
✓
Cost ReceiptsRetry logic, observability hooks, and per-query cost tracking — it behaves like prod, not a notebook.